· Mehdi Aroui · KI-Automatisierung · 4 min read
Multi-Agenten-Orchestrierung: Websites effizient bauen
Ein steuernder Agent, spezialisierte Subagenten, konsequentes Modell-Routing: An einem Vormittag entstanden 4 Blogartikel und 34 Hero-Bilder für mehrere Firmen-Websites. Was das gekostet hat und warum die Bilder teurer waren als der Text.

Multi-Agenten-Orchestrierung für Content-Produktion kombiniert drei Hebel: Modell-Routing nach Schwierigkeit, Anbieter-Routing für token-schwere Arbeit und Kontext-Disziplin durch isolierte Subagenten. Das Ergebnis: mehr Kontrolle über Kosten und Kontextgrenzen, nicht nur theoretisch.
Das Problem: Kontext läuft voll, Kosten laufen davon
Wer KI-Agenten ernsthaft für Produktionsaufgaben einsetzt, stößt an zwei Grenzen.
Das Budget. Ein Top-Modell für jede Kleinigkeit ist teuer. Wenn ein Agent eine Datei umbenennt, einen Pfad prüft oder ein kurzes Commit-Log schreibt, muss das nicht das teuerste Modell in der Runde erledigen.
Der Kontext. In einer langen Arbeitssitzung sammelt der Agent fortlaufend Zwischenergebnisse: Dateiinhalte, Build-Logs, Bestätigungen von 30 erzeugten Bildern. Irgendwann ist der Kontext voll. Die Qualität der Antworten sinkt, weil das Modell frühe Instruktionen verdrängt. Das Token-Budget ist weg, und die Arbeit ist halb fertig.
Der Plan: drei Hebel für Kosten und Kontext
Hebel 1: Modell-Routing nach Schwierigkeit
Nicht jede Aufgabe braucht das gleiche Modell:
- Einfache mechanische Arbeit (Datei-Writes, Strukturprüfungen, Vault-Notizen): günstiges Modell
- Mittlere Aufgaben (Texte, Verifikationen): mittleres Modell
- Hochrisiko-Entscheidungen oder komplexe Orchestrierung: teures Modell
Das klingt selbstverständlich, wird aber fast nie konsequent umgesetzt, weil es Planung vor dem Start erfordert.
Hebel 2: Anbieter-Routing für token-schwere Arbeit
Token-intensive Generierung lässt sich auf ein zweites Provider-Budget auslagern. Der Haupt-Orchestrator sieht nur das Ergebnis, nicht den Zwischenweg. Das schont das knappe Hauptbudget real.
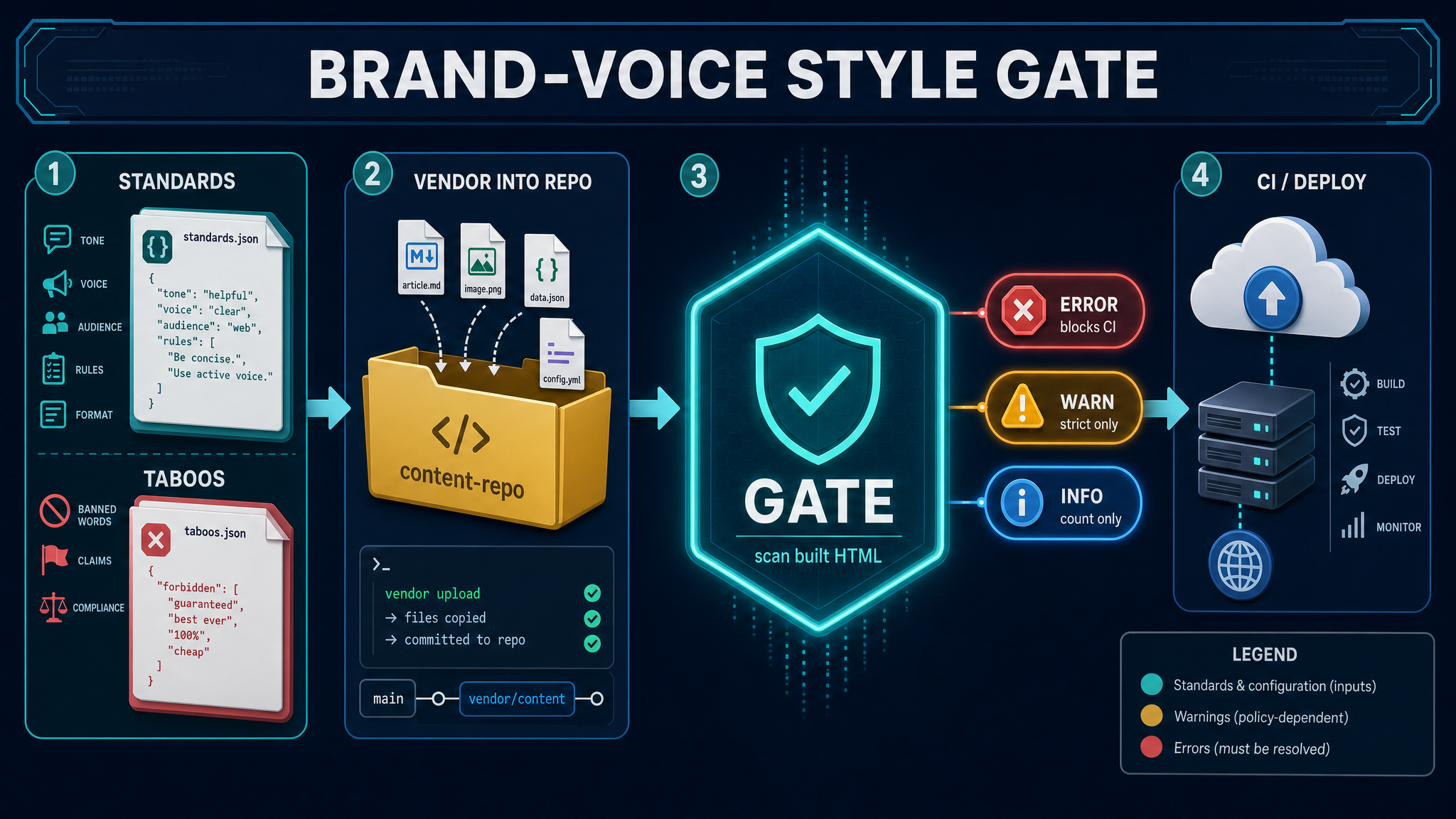
Hebel 3: Kontext-Disziplin durch Subagenten
Subagenten arbeiten isoliert. Sie bekommen eine Aufgabe, erledigen sie, liefern einen kurzen Bericht zurück. 30 Bild-Bestätigungen, ein 60-Dateien-Commit, lange Build-Logs: all das bleibt aus dem Hauptkontext draußen.
Der Lauf mit Zahlen
An einem Vormittag (24.05.2026) entstanden über mehrere Firmen-Websites hinweg 4 Blogartikel und 34 Hero-Bilder.
Preise (Stand Mai 2026, USD je 1 Mio. Tokens):
- Claude Sonnet 4.6: 3 USD Input / 15 USD Output (Vertrauensstufe hoch)
- Claude Haiku 4.5: 1 USD Input / 5 USD Output (hoch)
- GPT-5.2 / Codex: 1,75 USD Input / 14 USD Output (hoch bis mittel)
- gpt-image-2 in High-Quality 1536x1024: 0,20 USD pro Bild (mittel)
- Wechselkurs: rund 0,86 EUR je USD (hoch)
Was die Subagenten verbraucht haben:
- 8 Sonnet-Subagenten: rund 457.000 Tokens (Schreiben, Verifikation, Bild-Pipeline-Steuerung, Commit)
- 1 Haiku-Subagent: rund 100.000 Tokens (Vault-Notiz aktualisieren)
- Codex über OpenAI: 3 Läufe für Texte und ein Bild-Manifest
- Bilder gesamt: 34 Stück über gpt-image-2
Kosten (80% Input, 20% Output, kein Cache-Rabatt, bewusst konservativ):
| Posten | Kosten |
|---|---|
| Sonnet-Arbeit | rund 2,50 USD |
| Haiku-Arbeit | rund 0,20 USD |
| Codex-Arbeit | geschätzt rund 0,40 USD |
| Haupt-Orchestrator | geschätzt rund 1,50 USD |
| 34 Bilder | 6,80 USD |
| Summe | rund 11 bis 12 USD, circa 10 EUR |
Die wichtigste Erkenntnis: Sobald man konsequent das günstigste ausreichende Modell wählt, ist nicht mehr der Text der teuerste Posten. Von rund 11 USD entfielen 6,80 USD auf die Bilder. Der gesamte Schreib-, Verifikations- und Orchestrierungsaufwand kostete weniger als die Bilder allein.
Was der Vergleich sagt
Wer dieselbe Arbeit ohne Routing erledigt, also alles in einer einzigen Sitzung im Top-Modell, zahlt beim reinen Rechenanteil grob das Zwei- bis Dreifache. Der Kontext wächst mit jedem Schritt. Jede neue Anfrage verarbeitet nicht nur die aktuelle Aufgabe, sondern alle vorherigen Zwischenergebnisse.
Realistische Ersparnis für diesen Lauf: rund 50 bis 65% beim Rechenanteil. Die Bildkosten bleiben in beiden Varianten gleich.
Der eigentliche Gewinn ist nicht nur die Ersparnis. Ein erschöpfter Kontext im Haupt-Agenten bringt die gesamte Produktion zum Stillstand.
Was sich bewährt hat und was nicht
Was mehr Zeit gekostet hat: Das Bild-Manifest. Die Schnittstelle zwischen Text-Subagenten und Bild-Subagenten braucht ein klares Format, sonst entstehen Korrektur-Runden, die Token kosten ohne Mehrwert.
Was sofort funktioniert hat: Das Prinzip der kurzen Rückmeldung. Subagenten bekommen die Anweisung, nur ein einzeiliges Ergebnis zurückzumelden (“4 Dateien geschrieben, kein Fehler”). Kein Rohtext, keine Zwischenschritte. Das hält den Kontext des Orchestrators über die gesamte Sitzung stabil.
Wichtige Erkenntnis: Modell-Routing funktioniert nur, wenn Aufgaben sauber abgegrenzt sind. Sobald eine Aufgabe sowohl inhaltliche Entscheidungen als auch mechanische Schritte vermischt, läuft sie automatisch auf dem teureren Modell.
Häufige Fragen
Für welche KMU-Anwendungen lohnt sich Multi-Agenten-Orchestrierung? Für alle wiederkehrenden inhaltlichen Aufgaben mit klarer Struktur: monatliche Reports, Dokumentationspflege, Angebotsvorbereitung, strukturierte Auswertungen. Sobald eine Aufgabe regelmäßig und vorhersehbar ist, lohnt der Einrichtungsaufwand.
Wie hoch ist der Einrichtungsaufwand? Einmalig ein bis zwei Tage für Prozess-Design, Subagenten-Struktur und Qualitätsprüfungen. Danach läuft ein strukturierter Produktionslauf ohne manuellen Eingriff durch.
Welche KI-Anbieter eignen sich für das Anbieter-Routing? Anthropic (Claude) und OpenAI (GPT/Codex) sind die praxiserprobten Optionen. Welcher Anbieter für welche Teilaufgabe besser passt, hängt vom konkreten Use Case ab. Techiota evaluiert das im Kontext Ihres Vorhabens.
Techiota richtet Agenten-Pipelines für KMU ein, klärt das Modell-Routing und begleitet die ersten produktiven Läufe. Wenn Sie wissen möchten, wie das für Ihren Betrieb konkret aussehen könnte, sprechen Sie uns an über techiota.de.